【C++】ラムダ式の再帰では戻り値の型を書く
ラムダ式で再帰をしたい場合は,戻り値の型を明示した方が安全そう.
戻り値の型を明示しない次のコードは正常に動作する.

一方,14-15行目を削除した次のコードは怒られる.

error: use of ‘main()::<lambda(auto:23, int, int)> [with auto:23 = main()::<lambda(auto:23, int, int)>]’ before deduction of ‘auto’ 17 | f(f,nxt,now); | ~^~~~~~~~~~~
エラー内容は「'auto'の推論前にautoを使用しているよ」という内容.
型が確定する前のautoを使用しているから怒られているっぽい.
ラムダ式の内部で,再帰呼び出し前にreturn文があると怒られず,無いと怒られる.
C++の仕様を調べたが,なぜなのかはよく分からず.
この辺りが関係しそう.
ちなみに,戻り値の型を明示すると怒られなくなる.

上記のことを気にしなくて済むように,常に返り値の型を明示する癖を付けておけば良さそう.
【随時更新】競プロでちょっと便利な実装Tips(C++)
便利だなーと思ったTips.(C++)
vectorの要素出力で,スペース区切りで最後に改行
for(int i = 0; i < vec.size(); i++) { cout << vec[i] << " /n"[i + 1 == vec.size()]; }
vector⇄set の生成
コンストラクタを使う.
// vector→set set<int> st(vec.begin(), vec.end()); // set→vector vector<int> vec(st.begin(), st.end());
set, mapの要素全取得
for-eachを使う.
// set for(auto val : st) { // ... } // map for(auto [key, val] : mp) { // ... }
pair, tupleの分解
構造化束縛を使う.
//pair auto [a, b] = p; // tuple auto [a, b, c] = t;
グリッドで隣接する八方を調べる
差分-1~1の二重for.dx=0, dy=0はcontinueすることに注意!
// x: 今見ているマスのx座標 // y: 今見ているマスのy座標 for(int dx = -1; dx <= 1; dx++) { for(int dy = -1; dy <= 1; dy++) { if(dx == 0 && dy == 0) continue; int nx = x + dx; int ny = y + dy; // ... } }
枠内チェックも一緒にしちゃう版.
for(int nx = max(x - 1, 0); nx <= min(x + 1, h - 1); nx++) { for(int ny = max(y - 1, 0); ny <= min(y + 1, w - 1); ny++) { if(nx == x && ny == y) continue; // ... } }
【ゲーム】HTTPステータスコードで神経衰弱するゲームを開発しました
Reactで何か作りたいけどネタがない,,,
そういえばHTTPステータスコード忘れてきてるな,,,
せや!!!
\\爆誕//
HTTPステータスコード神経衰弱(プレイページ)
開発リポジトリ

目次
どんなゲーム?
HTTPステータスコードはWEB開発の基本中の基本です.
そんなHTTPステータスコードを楽しみながら覚えられるようなゲームを作りました.
以下の3つのモードで遊ぶことができます.
- CPUと対戦: コンピュータと対戦できます.強さは「弱い」「普通」「強い」から選べます.
- 2人で対戦: ローカルで2人で対戦できます.
- トレーニング: 1人でプレイできます.
工夫したところ
今回は実装練習重視だったのと,個人的にシンプルなUIが好きなので,UIはAnt Designをそのまま使っています.
画面は「モード選択」「ゲーム設定」「プレイ画面」の3つの画面を作成し,以下のことを意識しました.
- 画面の共通化: どのモードでも画面構成はほぼ同じなので,選択したモードやゲーム設定をContextに持たせて画面の出し分けを行い,実装量を減らしました.
- UIとロジックの分離: 実装していると,カードの出し分けを行うUIの処理と神経衰弱のゲームロジックの処理が混在した巨大なファイルが出来上がってしまいました.そこで,UI処理はpage.tsxのそのままに,ゲームロジックをカスタムフックに切り出して分離しました.かなり実装しやすくなりました.
開発で難しかったところ
2つあります.
その1: 再レンダリングのタイミング
実装では,カードの表・裏の状態はopenedというboolean型配列のstateで管理していました.
カードのonClick関数が走ると,openedをtrueに変更することでそのカードが裏返るCSSを当て,再レンダリングされた瞬間から500msかけて裏返る(ように見える)ようになっています.
1枚目のカード選択はそれで良いのですが,2枚目のカード選択後は,裏返ってから,ペアならばカードが除去されペアでなければ再び裏返るようにしないといけません.
Reactは基本的にstateを更新する処理が実行されると,すぐに再レンダリングしてしまいます.
そのためonClick関数の中でopenedをfalseに戻したり,カードが場にあるかを管理する別のstateを更新してしまうと,カードが表向きになるモーションが起こらなかったり,表向きになる前に除去されたりしてしまいます.
理想は「onClickが走る→カードの再レンダリング→裏返るモーション→カードの再レンダリング→再び裏返るモーションor除去」です.
つまり,onClickが走るタイミングと2回目の再レンダリングには時差があります.
そこで今回は,onClickの中でsetTimeoutを呼び出し,1500ms後に再度stateを更新して再レンダリングするようにして実現しました.
setState関数が実行するタイミングや,setState関数に値では無くコールバック関数を渡した場合の挙動などが勉強になりました.
CPUの連続した選択もsetTimeoutをネストした1ターン分の処理を,再帰で呼び出して実現しています.(setTimeoutのネストは正直好きではないですが,,,)
その2: CPUのアルゴリズム
CPUのカード選択のアルゴリズムは思っていたより大変でした.
過去に裏返った既知のカードの情報から強さに応じて選択の仕方を変える実装が難しかったです.
ペアを作るかどうかは生成した乱数が強さに応じた閾値を超えるかどうかで判定すれば良いです.*1
ただペアを作らなかった場合にわざと外す2枚を選ぶのか,未知のカードの中から選ぶのかは場の状況に依ります.(すべて既知ならわざと外さないといけないし,未知のカードがあるならまずはそこから1枚選ぶ)
結局は人間の行動を模倣しているのですが,場の状況と確率的判定と組み合わせた選択をコードに書き起こすのに苦労しました.
もしかしたら上手いまとめ方があるのかもしれません.
プレイ中,CPUのターンが1枚選んで終わってしまうことがあります.発生条件や原因はよく分かっていません.アルゴリズムのバグではないはずです.バグってたらごめん!
また,UIへの反映も工夫したところです.
先述の通りstateの更新と再レンダリングは密接な関係があるので,先にCPUの選択するカードをすべて決定してから,setTimeoutを呼び出す関数を再帰して1手ずつ描画しました.*2
競プロやってなかったら「そうだ,京都,行こう.」のノリで「そうだ,再帰,実装しよう.」なんて思わないぞ!!!?!
既知のカードの情報はUIには直接関係ないのでstateではなくrefで管理することも意識しました.
最後に
せっかくなのでGitHub ActionsでGitHub PagesのBuild&Deployも行ってみました.
deployブランチを変更するだけでBuild&Deployしてくれるのはかなり楽で嬉しいですね.
次は何作ろうかな~!!(ネタが無い)
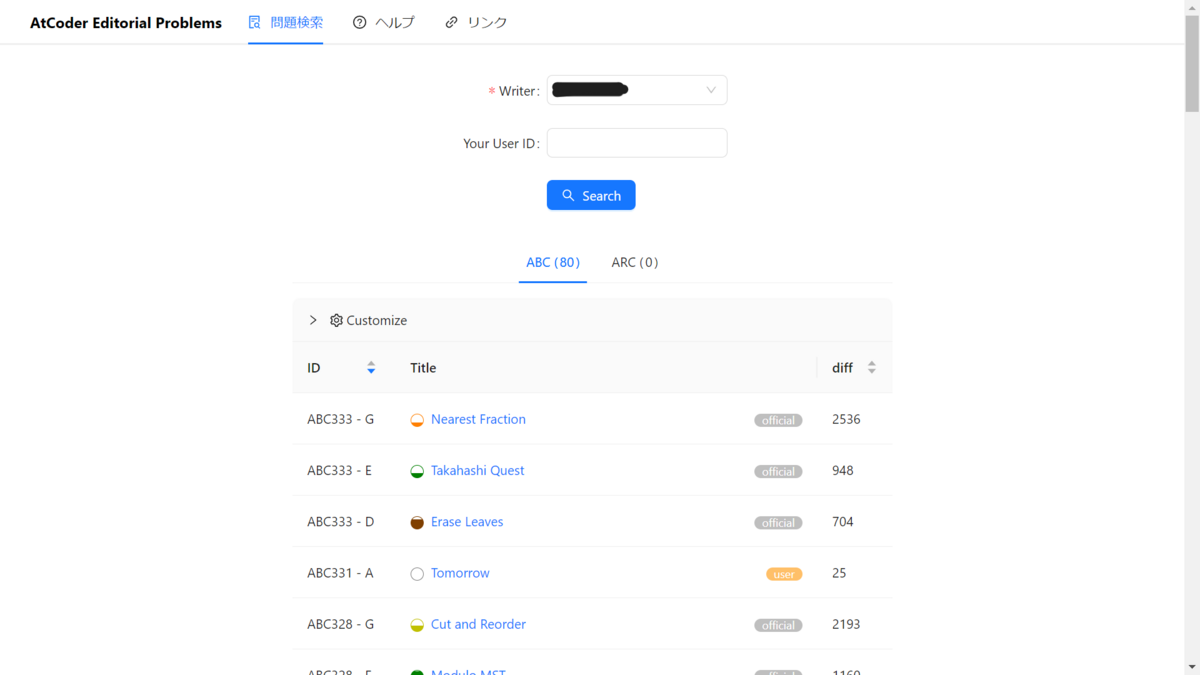
【精進支援ツール】AtCoder Editorial Problemsを開発しました
AtCoderの問題を解説の筆者から検索することができるWebアプリ「AtCoder Editorial Problems」を開発しました!
開発リポジトリ: AtCoderEditorialProblems(GitHub)
これは使用した技術や工夫の記録です.
目次
AtCoder Editorial Problems(AEP)とは?
AEPは,AtCoderの問題を解説の筆者から検索することができるWebアプリです.
PDFで解説を配布していた昔のコンテストを除き,ABC/ARCのすべての公式/ユーザー解説を検索することができます!
「この人の解説は自分に合っているな~」と思ったときに超便利です.
開発中のあれこれ
Writer(問題を書いた人)に得意不得意がある人は一度は思ったことがあると思います.
「苦手Writerの対策をしたいな~~~~」
って.
これが開発のきっかけでした.
それまではWriter経験のある人が自身のブログにまとめる程度で,まとまって情報を入手できる場所がありませんでした.
なので作ることにしました.
ちょうど「一度はWebアプリを作ってみたいけど題材が無い状態」だったので,自分の学習のためにももってこいのアイデアでした.
公式解説の筆者がその問題のWriterだと思っていたので(たぶん多くの人がそう思っている),当初はそのように定義したWriterから問題検索できるように開発していました.
しかし目標だった年内リリースの期限直前!! 12/30に,
- 公式に公表されていない「問題ごとのWriter」を決めつけてサービス提供するのはどうなのか.
- おっと,Writerが解説も書いているとは限らないぞ.
- はたまた1問題1Writerとも限らないぞ.
などの懸念があり,急遽「Writerから問題検索できる」から「解説の筆者から問題検索できる」に変更しました.(リリース直前にサービス内容変更ができるのも個人開発の良くない醍醐味?)
流石に変更に合わせてシステムを全改修するのは間に合わないので,一旦公式の筆者だけ検索できる状態のままリリースし,4日でPDF以外のすべての解説を検索できるようにしました.
結果としてやりたかったことがそのまま形になった訳ではないですが,解説の好みも人によってはあると思うし,自分もあるので,これはこれで「確かにあると便利なサービス」だったのではないかなと思います.
ちなみに検索結果で公式解説なのかユーザー解説なのかが分かるので,当初描いていた「Writerからの問題検索」という使い方もできます.しめしめ.
開発で大切にしたこと
下手にいろいろな技術に手を出さない
高度な技術や便利なライブラリに下手に触れませんでした. 理由としては,
- 開発は「自分の学習のため」でもあり基礎を学びたかったから.
- 高度な技術はそれなりに学習コストが高いから.
- 初めての技術が多すぎると脳がパンクするから.
- 初めての技術をいろいろ採用しすぎて,「結局なにもわからなかった」となるのは避けたかったから.
- よく分からない技術をよく分からないままに使用するのは嫌だったから.(セキュリティ的にもこわい)
です.
具体的にはAWSやReact,Next.jsの基本的な使い方の習得に集中したかったので,便利なライブラリとかIaCとかは採用しませんでした.
あえて泥臭い実装をすることで,いざ高度な技術や便利な技術を学んだときのインパクトが強く,そのときの学習効果も高いと思っています.
また,例えばDBだと本音はDynamo DBを使ってみたかったのですが,やるならDB設計からちゃんと学びたくそれはそれで学習に時間がかかるので,使用経験のあるPosgreSQLを採用しました.
年内リリース
「個人開発のコツは期限を決めること!!」(らしい)
7月にTwitterで期限を宣言しました.
実は開発の練習がてら、AtCoder関連の便利Webアプリを作ることにしました
— あじのこ (@Ajinoko33) 2023年7月12日
サービス内容は大したものではないですが、完成したら使ってやってください
(技術の使い方から勉強しないといけないで、完成までめっっちゃ時間かかります、目標は年内)
この時点ではReactは知っていたもののNext.jsは名前も聞いたことが無く,AWSも「なんかAPI Gateway+Lambdaで簡単にAPIがつくれるらしい」程度でした.
別に期限を決めなくても開発はするのですが,決めた理由は以下の通りです.
- 割と誰でも思いつき,かつ開発も難しくはないであろう単純なサービスだったので,誰かに先を越される可能性が高いと感じたため.
- 長期間作り込んでリリースしたもののウケなかったら悲しいため.
- 早めにニーズを確認したかったため.
平日は仕事にエネルギーを費やしていたので,土日に開発を進めていました.
結果,12/31 19:05にリリースすることができました!
ギリギリになったのは思っていたよりもデプロイに手間取ったためです.
年末恒例の紅と白に分かれて歌合戦する某番組が始まる前で良かった!
採用した技術
- バックエンド(AWS)
- API Gateway
- Lambda(Python)
- RDS(PostgreSQL)
- EC2(RDS設定用の踏み台サーバー)
- Pythonライブラリ
- Requests: HTTP通信.外部API呼び出しやAtCoderの解説一覧ページ取得に利用.
- Beautiful Soup: HTMLやXMLをスクレイピング.解説の筆者を取得するために利用.
- Powertools for AWS Lambda: Lambda用の公式ツールキット.パラメータのバリデーションで利用.
- フロントエンド
- Next.js
- React
- Taliwind CSS
- Ant Design
- TypeScript
- その他
- GitHub Pages
採用しなかった技術
今後リファクタリングや学習の一環で採用する可能性はあります.
- Chakra UI
- Ant Designと両方使ってみた結果,理想のUIを実現するには使いにくいと感じたため.
- 検索機能付きSelectが公式には無かったため.非公式で誰かがGitHubに上げていたが理想のUIではなかった.
- Dynamo DB
- 先述の通り,期限に対して学習コストが高いため.
- 独自ドメイン
- 最初は独自ドメインに憧れていたが時間的に今後も個人開発を行っていくとは限らないため.取得はいろいろ開発するようになってからでも遅くはない.
- このアプリ特有のドメイン取得もチラついたが,サ終後に手放したドメインが悪意を持ったユーザに利用され,Twitterやこの記事で宣伝時に貼ったURLやブックマークからアクセスしたら変なサイトが開いて困る人が出るかもしれないと考えたため.
- そんなときにちょうど変なドメイン取るな!!!.netを見かけ,強く決意したため.
- GitHub Actionsによるデプロイ
- 期限まで時間が無かったため妥協.
こだわりポイント
- UX
- 動きのある派手な画面よりシンプルで使いやすいのが一番.
- 提示する情報や機能も最低限に.
- 例えばAGCの問題を収集しても良いが,ほとんどのユーザにとっては不必要なタブが生まれる.選択時に認知負荷を少しでも低減させるために無駄なタブは削ぎ落とした.
- 問題や解説の筆者の情報は自前のDBに保存
- Sliderによるdiffフィルター
- 大発明では!?
- 数値で範囲指定する方法など考えたが,色でフィルタリングできるSliderが直感的で良いと感じた.
- Sliderを少しでも動かす度に範囲内の色を再レンダリングしているため,よく見ると少しガタつくのが惜しい.
最後に
自分でイチから考えて,好きなサービスを開発するのって楽しい!!
特に「ここはこうした方がユーザーは使いやすいんじゃないか」とユーザー指向で作っていくのが楽しかったです.
また,規模や出来にかかわらず自力で一つサービス開発した経験って,結構大きいと思いました.1年前の自分には全く考えられません.
これは自分への教訓ですが,どんなに汚い実装だと自分で思っていてもどんどん実装していくのが良いです.
自分は変数名一つでも考え込むので,後々相当悪い影響が想像できる場合でない限りは「一旦これでいいや」として先に進み,「DB構築できた」とか「API作ってブラウザから叩けた」とかどんどん実績解除していくのがモチベにも繋がって良いと思いました.
この記事が,誰か(読み返している未来の自分もだぞ)の開発のきっかけになれば嬉しいです.
次は何作ろうかなー.
ここまで読んでいただきありがとうございました!
AHC022 参加記 (RECRUIT 日本橋ハーフマラソン 2023夏)
2023/08/11(金)12:00 ~ 08/20(日)19:00 の約1週間,RECRUIT 日本橋ハーフマラソン 2023夏(AtCoder Heuristic Contest 022) が行われました.
AHC参加5回目,Heuristic緑色の私は暫定427位/最終421位というまずまずの結果でしたが,取り組む中でいろいろ勉強になったので参加記を書きます.
前回の参加記は参加3回目のときで,人によっては1回飛んでるように感じられるかもしれません.気のせいです.
目次
問題概要
N個のワームホールがあり,入口と出口の対応を当てるゲーム.入口と出口は1対1に対応しており,異なる入口から入って同じ出口に出ることはない.
手がかりになるのは,温度.
あらかじめグリッド上の全てのマスに温度を設定しておき,任意のワームホールから入って,対応する出口から好きなだけ動いた位置で計測した温度を頼りにする.
難しいポイントは,
- 計測段階ではどの出口が対応しているのかは分からない
- 計測値は「真の温度+ノイズ」.ノイズはめっちゃ大きいケースもある
考察
とりあえずサンプルコードを提出して出席点をいただく.
絶対得点3,467,623点.
サンプルコードでは,各出口に10刻みで温度を設定して目印を付け,出口の計測値と最も近いものを推定結果としていた.
正直,これより良い解法がパッと思いつかなかったので,今回もダメかなーと半ば諦めモード.
せめて温度変化をなだらかにした方がコストが減ってマシになりそう.
それならグリッドの中心を0にして縁のほうへ離れるほど高温にしたほうが全体的によさそう.
じゃあ中心に近い出口から順に10刻みで温度をつけて,全体を均せばよさそう.
中心に近い出口から温度を設定する:各出口について中心からのマンハッタン距離を計算し,昇順ソートしたものに10刻みで温度設定.
全体的に均す:出口以外は周囲4マスの平均をとる.これを10,000回繰り返すと全体的にいい感じになった.(多分安定するまで10,000回もいらない)

75,704,338点.1ケタ伸びた!
温度分布はマシになったが,出口は10刻みなのでちょっとノイズが大きくなるだけで精度が悪化する.
ノイズの影響をもろに受ける1点計測だから良くないのかな.
周囲4方向にちょっと離れたマスの温度も計測して,計5点の平均を推定値にしてみたけど,あんまり良くならなかった.
さて,何も思いつきません.助けて~.
どうにもならないので,過去の類似のAHCを探して,その上位解法をパクる参考にすることにする.
そういえば,「ノイズ付きのoutputからinputを推定する」という構造がAHC016 Graphoreanに似ている.
公式解説やユーザ解説を見ていく.
上位解法は解説を読んでもよく分からない.公式解説を見てみると,何やら確率を使ってる.いかにも推定って感じ.
ふむふむ,各inputから計測値(output)が生まれる確率を計算し,最も高いものを推定結果としているのか.
これなら今回もできそう.
今回は入力で与えられるSを使って,平均0,標準偏差Sの正規分布からサンプリングした値がノイズとなっている.
これより,ある計測値に対し,各出口で真の温度とSの値を元にz得点を計算し,正規分布で±z得点以上の範囲の面積(確率)を算出.確率が最も高いものを推定結果とする.
z得点の計算は良いとして,面積の算出はどうやるの?積分するプログラム書けるの??
知らん知らん!そんなもんは知らん!!
標準正規分布表からベタ書きじゃい!!!

はい提出提出~!!
211,911,324点!!!
うぇ~~~い(また1ケタ伸びた)
そしてこのまま,ちょっとだけパラメータ調整して最終提出を迎えました.
最終提出
- 配置
- 各出口に,中心からマンハッタン距離で近い順に10刻みで温度を設定.
- その後,配置時コストを減らすために全体を均す.
- 計測
- S=1の場合
- 出口を1点計測.
- 各出口についてその計測値以上に誤差のある値が計測される確率(の半分)を算出.最も確率の大きいものを推定結果とする.
- S>1の場合
- 出口1点と周囲4方向に7マス離れた地点の,計5点計測.
- 計測した5点それぞれでS=1と同様に確率を算出.それらを掛け合わせた確率が最も大きいものを推定結果とする.
- S=1の場合
結果



次に生かせそうな知識・テク
- output(計測値)が得られる確率から推定する
- 推定の基本的な考え方だと思う.
- 詰まったら過去の類似回を参考にする
- 今回に応用できるかな?などと考えるので記憶に残りやすい.
- 簡単なケースでは着実に点を取る
- AHC016公式解説でwataさんが「今回の点数計算式を見ると,ノイズが大きいときに1個でも多く当てるよりも,ノイズが小さいときに確実に当てるのが大事」というようなことを仰っていた.
- 今回もそうなのかは分からないが,小さいノイズのケースで確実に当てるのは,同様のアルゴリズムを採用した集団の中でも高い順位を狙うという点で重要だと思う.今回はS=1だけ低コストで確実に当てるようにした.
- 小数の積はlogを使う
コメント
【解説】ABC310 B - Strictly Superior
執筆時レート:水色
問題文→https://atcoder.jp/contests/abc301/tasks/abc310_d
公式解説→https://atcoder.jp/contests/abc301/tasks/abc310_d/editorial
目次
問題
個の商品がある.
各商品には価格と機能が以下のように定義されている.
- 商品
の価格は
- 商品
個あり,
番目の機能は
以上
以下の整数
として表される
このとき,以下の条件を全て満たすような商品 ,商品
の組は存在するか?
- 商品
であるか,商品
制約
- 入力は全て整数
解説
まずは全探索を考えるのが基本.
全ての組 について,問題文の条件を全て満たすものがあるか調べる.
問題文の条件が何を意味しているのかが分からないときは,言葉で表現してみると分かりやすくなるかも.
これは「商品 の方が安いか,同じ価格」.
- 商品
これはそのままの意味.
「商品 は商品
以上に多機能」とも言い換えられる.
価格については「商品 の方が安い」ということ.
機能についてはそのままの意味だが,二つ目の条件を満たしているときは,「商品 の機能
商品
の機能
」,つまり「商品
の方が多機能」ということになる.
このような3条件を全て満たす組があるか調べれば良い.
計算量はどうだろう.
調べる組み合わせの数は で,ある組
について各条件の判定に,
の比較をすれば良いので
- 商品
- 価格の比較も機能数の比較も
なので,合わせて
これだと全体の計算量は, となり,今回の制約だとまあ間に合うかな,という感じ.(C++の処理の速さを信じて)
他の言語だと間に合わないかもしれないし,定数倍がこわいときは,set(集合に対して所属判定を で行える構造体)を使えば高速化が図れる.
具体的には,判定では がボトルネックになっているので,商品
の機能をまとめたsetに対して商品
の各機能が含まれているかを調べれば,判定は
,全体で
になる.
さらに,各商品について「あり得る 個の機能のうち持っているものにフラグを立てる」という管理をすれば,二つ目の条件の判定を
,全体で
に落とせる.
実装
解法.余裕で間に合う.
提出
#include <bits/stdc++.h> using namespace std; int main(){ // 入力を受け取る int n,m; cin>>n>>m; vector<int> p(n); vector<vector<int>> func(n); for(int i=0; i<n; i++) { cin>>p[i]; int c;cin>>c; for(int j=0; j<c; j++) { int f; cin>>f; func[i].push_back(f); } } // 判定 for(int i=0; i<n; i++) { for(int j=0; j<n; j++) { if(p[i]>=p[j]){ // 一つ目の条件を満たしている // 二つ目の条件「商品jが商品iの機能をすべて含んでいるか」を調べる bool inc=true; // 商品iの機能をすべて含むか? for(auto fi: func[i]) { // 商品iのある機能fiが商品jにあるか? bool exist=false; for(auto fj: func[j]) { if(fi==fj) exist=true; } // 無ければすべて含んでいないということ if(!exist) inc=false; } if(!inc) continue; // ここまでで二つ目の条件を満たしている // 最後の条件を満たすか調べる if(p[i]>p[j] || func[i].size()<func[j].size()) { // すべての条件を満たしている! cout<<"Yes"<<'\n'; return 0; } } } } // すべての組を調べても無かった cout<<"No"<<'\n'; return 0; }
setを使った 解法.
提出
#include <bits/stdc++.h> using namespace std; int main(){ // 入力を受け取る int n,m; cin>>n>>m; vector<int> p(n); vector<set<int>> func(n); for(int i=0; i<n; i++) { cin>>p[i]; int c;cin>>c; for(int j=0; j<c; j++) { int f; cin>>f; func[i].insert(f); } } // 判定 for(int i=0; i<n; i++) { for(int j=0; j<n; j++) { if(p[i]>=p[j]){ // 一つ目の条件を満たしている // 二つ目の条件「商品jが商品iの機能をすべて含んでいるか」を調べる bool inc=true; // 商品iの機能をすべて含むか? for(auto fi: func[i]) { // 商品iのある機能fiが商品jに無ければ,すべて含んでいないということ if(!func[j].count(fi)) inc=false; } if(!inc) continue; // ここまでで二つ目の条件を満たしている // 最後の条件を満たすか調べる if(p[i]>p[j] || func[i].size()<func[j].size()) { // すべての条件を満たしている! cout<<"Yes"<<'\n'; return 0; } } } } // すべての組を調べても無かった cout<<"No"<<'\n'; return 0; }
解法.
提出
#include <bits/stdc++.h> using namespace std; int main(){ // 入力を受け取る int n,m; cin>>n>>m; vector<int> p(n); vector<int> c(n); vector<vector<bool>> func(n,vector<bool>(m)); for(int i=0; i<n; i++) { cin>>p[i]>>c[i]; for(int j=0; j<c[i]; j++) { int f; cin>>f; f--; func[i][f]=true; } } // 判定 for(int i=0; i<n; i++) { for(int j=0; j<n; j++) { if(p[i]>=p[j]){ // 一つ目の条件を満たしている // 二つ目の条件「商品jが商品iの機能をすべて含んでいるか」を調べる bool inc=true; // 商品iの機能をすべて含むか? for(int k=0; k<m; k++) { // 機能kを商品iはもっているが商品jはもっていなければ,すべて含んでいないということ if(func[i][k] && !func[j][k]) inc=false; } if(!inc) continue; // ここまでで二つ目の条件を満たしている // 最後の条件を満たすか調べる if(p[i]>p[j] || c[i]<c[j]) { // すべての条件を満たしている! cout<<"Yes"<<'\n'; return 0; } } } } // すべての組を調べても無かった cout<<"No"<<'\n'; return 0; }
ABC304 F - Shift Table
執筆時レート:水色
問題文→https://atcoder.jp/contests/abc304/tasks/abc304_f
公式解説→https://atcoder.jp/contests/abc304/editorial/6511
目次
問題
高橋君と青木君は 日間アルバイトをする.
高橋君のシフト表は文字列 で与えられ,
が
#ならば 日目に出勤,
. ならば 日目に欠勤する.
一方,青木君は以下の手順でシフト表を作成する.
でない
の順に
日目の勤怠が
※ の値が異なる場合でも最終的なシフトが等しくなる場合があることに注意.
日すべてについて高橋君と青木君の少なくとも一方が出勤することになったとき,青木君のシフト表として考えられるものの個数を
で割ったあまりを求めよ.
制約
以上
以下の整数
は長さ
#,.からなる文字列
方針
サンプルケース1で考えてみる.
##.#.#
青木君のシフト表を とする.
で考えてみる.
高橋君が欠勤する日は青木君は必ず出勤しなければならないので,最初の 日間のうち何日かは出勤で確定する(
?は出勤か欠勤か選べる).
?##
よって の場合では
で
通り!
同じように他の でも求めて合計すればOK!
としたいところだが,?を#にしたときの ######は,
でも生成でき,重複して計上してしまう.
問題は重複をどう排除するか?になる.
このようなとき,(多分)2通りの考え方がある.
- パターンと1対1対応するものを数える
- とりあえず重複を区別して数えてからダブりを引く
1.は今回だとTの最小周期の文字列に対応させるという考え方.
例えば ######の最小周期は#なのでこれだけを直接数えるように頑張る.
でもムズカシイ.
2.は, を全探索してどこかのタイミングでダブりを引く.
を固定したとき,重複を区別すると
というのは簡単.
どのようにしてダブりを引くか?
######を計上するのは1.と同じように最小周期で数えるとして, がそれ以外の周期のときでは計上しないようにしたい.
と固定して考える.
.##.##のような,「 が最小周期である場合」はここで初めて計上する.
一方,######のような,「 が最小周期でない場合」は,
が最小周期のときに計上してるはずなので,ここでは計上しないようにする.
では「 が最小周期でない場合」を引くために,最小周期と
の関係について調べてみる.
最小周期を とすると弱周期性補題より
も周期.
であり,
と仮定すると
が最小周期であることに矛盾するので,
.
よって
は
の約数である.
つまり,「最小周期 でない
の約数」が成立する.
よって,各 では「
が最小周期である場合」を計上しているので,ある
が最小周期である場合の数は,
で求められる.
が小さい方から全探索すればよい.
計算量
の約数の個数を
とする.
各 について,
?の個数を数えるのに ,ダブりを引くのに
かかるので,結局
かかる.
よって,最終的な計算量は となる.
今回の制約( )では,Nの約数の個数は高々128個なので十分高速である.
実装
https://atcoder.jp/contests/abc304/submissions/41989568
#include <bits/stdc++.h> using namespace std; #define rep(i,n) for(int i=0; i<n; i++) /* Modint構造体(省略) */ // 約数列挙 vector<ll> divisor(ll n){ vector<ll> ret; for(ll i=1;i*i<=n;i++){ if(n%i==0) { ret.push_back(i); if(i!=n/i) ret.push_back(n/i); } } sort(ret.begin(),ret.end()); return ret; } int main(){ int n;cin>>n; string s;cin>>s; // nの約数列挙 auto divs=divisor(n); // rem[i]:=最小周期がiである場合の数 vector<mint> rem(n+1); // p2[i]:=2のi乗 vector<mint> p2(n+1); p2[0]=1; rep(i,n) p2[i+1]=p2[i]*2; for(auto m:divs){ if(m==n) continue; // 出勤/欠勤を選べる日数を数える int cnt=0; vector<bool> must(m); rep(i,n) { if(s[i]=='.'){ must[i%m]=true; } } rep(i,m) if(!must[i]) cnt++; // 重複を区別した場合の数 rem[m]=p2[cnt]; // ここからダブりを引く for(int i=1;i<m;i++){ if(m%i==0){ rem[m]-=rem[i]; } } } // remの合計が答え mint res=0; for(auto r:rem) res+=r; cout<< res <<'\n'; return 0; }